Hands-on Scala Programming
4.2 不変コレクション
配列は低レベルのプリミティブ型ですが、ほとんどのScalaアプリケーションは、その可変型と不変型のコレクション――Vector、List、Set、Map――を基盤として構築されています。これらの中でも、不変コレクションは特に一般的です。 不変コレクションは、予期しない変更によるバグのクラス全体を未然に防ぐことができ、特にマルチスレッド環境において有用です。スレッド間で共有する際にスレッドセーフ性を心配する必要がなく、安全に不変コレクションを受け渡しできます。ほとんどの不変コレクションは構造的共有(4.2.2)を採用しており、更新されたコピーを効率的に作成できるため、パフォーマンスが最重要視されるコード領域を除いて、あらゆる場面で活用可能です。
4.2.1 不変Vector
Vectorは固定サイズの不変線形シーケンスです。汎用的なシーケンスデータ構造として適しており、ほとんどの操作において効率的なO(log n)のパフォーマンスを提供します。
val v = Vector(1, 2, 3, 4, 5)
v: Vector[Int] = Vector(1, 2, 3, 4, 5)
@ v(0)
res42: Int = 1
@ val v1 = v :+ 1
v1: Vector[Int] = Vector(1)
@ val v2 = v.updated(2, 10)
v2: Vector[Int] = Vector(1, 2, 10, 4, 5)
@ val v2 = 4 +: v1
v2: Vector[Int] = Vector(4, 1)
@ v2
res44: Vector[Int] = Vector(1, 2, 10, 4, 5)
@ val v3 = v2.tail
v3: Vector[Int] = Vector(1)
@ v // 注意:`v`自体は変更されていません!
res45: Vector[Int] = Vector(1, 2, 3, 4, 5)
@ val v = Vector[Int]()
v: Vector[Int] = Vector()
@ v(0)
res46: Int = 0
配列とは異なり、a(…) = …のように要素を代入するとその場で変更されますが、Vectorの.updatedメソッドは変更を加えた新しいVectorを返し、元のVectorは変更されません。これは構造的共有(4.2.2)の仕組みにより、O(log n)という比較的効率的な操作となっています。同様に、:+や+:を使って要素を前後に追加した新しいVectorを作成する場合や、.tailを使って要素を1つ削除した新しいVectorを作成する場合も、すべてO(log n)の操作となります: Vectorは配列や他のコレクションと同様に、同じ操作セット(4.1)をサポートしています:ビルダー(4.1.1)、ファクトリメソッド(4.1.2)、変換処理(4.1.3)など。 一般的に、Vectorは、変更されないことが確実なシーケンスを扱う場合に便利ですが、その操作方法に柔軟性が求められる場面で特に有用です。ツリー構造を採用しているため、ほとんどの操作が比較的効率的に行えますが、要素のインプレイス更新が必要な場合や、先頭への要素追加・削除に関しては、配列や不変List(4.2.5)ほどの速度は出ません。
4.2.2 構造的共有
VectorはO(log n)の時間でコピーと更新操作を実現するため、木構造の一部を再利用する仕組みを採用している。 これにより木構造全体をコピーする必要がなくなり、「新しい」Vectorは古い木構造の大部分を共有しつつ、 わずかな修正のみで作成される。 大規模なVector v1を例に考えてみよう:
val v1 = Vector(1, 2, 0, 9, 7, 2, 9, 6, ..., 3, 2, 5, 5, 4, 8, 4, 6)
このデータ構造はメモリ上で木構造として表現され、その幅と深さはVectorのサイズに依存する:
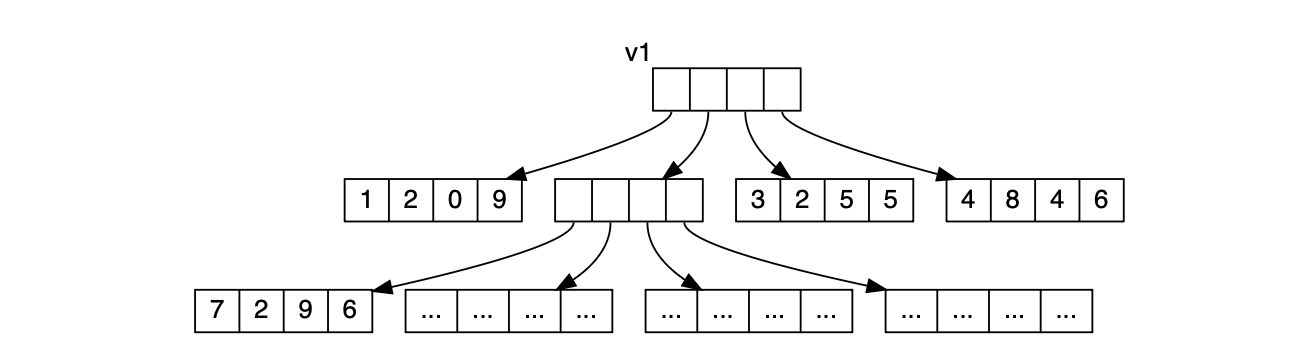
この例はやや簡略化されている - ScalaのVectorでは木ノードあたり4要素ではなく32要素が格納される (上記の例では4要素となっている)が、Vectorデータ構造の動作原理を説明するには十分だろう。 次に、例えば上記Vectorの5番目の値7を8に更新する場合の動作を見てみよう:
val v2 = v1.updated(4, 8)
v2
res50: Vector[Int] = Vector(1, 2, 0, 9, 8, 2, 9, 6, ..., 3, 2, 5, 5, 4, 8, 4, 6)
この処理では、更新対象の値までの直接経路上にある木ノードのみを更新コピーし、それ以外のノードは変更せずに再利用する:
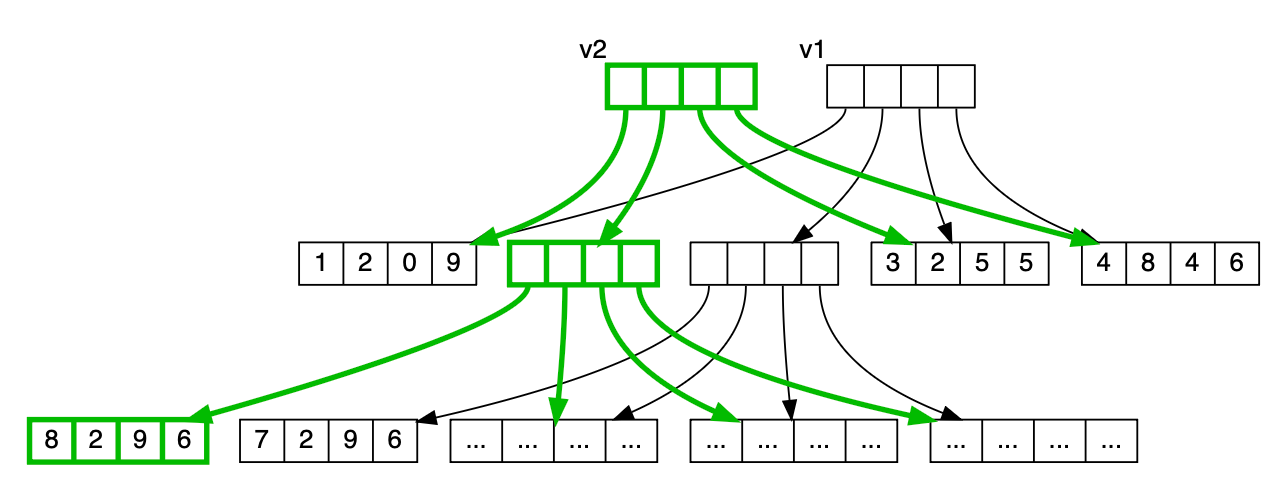
この例では9ノードからなるVectorの場合、実際にコピーが必要なのは3ノードのみである。大規模なVectorでは、 コピーが必要なノード数は木の高さに比例し、その他のノードは再利用可能である。この「構造的共有」こそが、 Vectorの更新コピーをO(log n)の時間で実現する鍵となっている。これは可変配列などのデータ構造を完全に コピーする場合のO(n)時間と比べて大幅に効率的である。
ただし、Vectorの更新操作には常にある程度のコピー処理が伴うため、可変データ構造をインプレースで更新する場合ほど 高速にはならない。パフォーマンスが重視されるケースで、頻繁にコレクションを更新する必要がある場合には、 より高速なO(1)の更新/追加/先頭挿入操作が可能なmutable ArrayDeque(4.3.1)や、コレクションのサイズが事前に 分かっている場合には生の配列を使用することも検討すべきである。 同様の木構造を持つデータ構造は、Immutable Sets(4.2.3)やImmutable Maps(4.2.4)の実装にも使用されている。
4.2.3 不変セット
Scalaの不変セットは、要素の重複を許さない順序なしのコレクションであり、効率的な
O(log n)の .contains メソッドを提供します。セットは + 演算子で構築でき、要素の削除には -
演算子を、複数のセットの結合には
++ 演算子を使用します。なお、重複する要素は自動的に削除されます:
@ val s = Set(1, 2, 3)
s: Set[Int] = Set(1, 2, 3)
@ s.contains(2)
res51: Boolean = true
@ s.contains(4)
res52: Boolean = false
セット内の要素の一意性は、コレクションに重複が含まれないことを保証したい場合にも有用です。 セットに対しては for ループで要素を反復処理できますが、要素の順序は定義されておらず、それに依存すべきではありません:
@ for (i <- Set(1, 2, 3, 4, 5)) println(i)
5
1
2
3
4
ほとんどの不変セット操作は、セットのサイズに対して O(log n) の時間計算量で実行されます。これは一般的な用途には十分な性能ですが、性能が不十分な場合には、より高速な Mutable セット(4.3.2節)を使用することも可能です。 セットは、すべてのコレクションに共通する標準的な操作セットもサポートしています。
4.2.4 不変マップ
不変マップはキーと値の順序なしコレクションであり、キーによる効率的な検索が可能です:
val m = Map("one" -> 1, "two" -> 2, "three" -> 3)
m: Map[String, Int] = Map("one" -> 1, "two" -> 2, "three" -> 3)
m.contains("two")
res58: Boolean = true
m("two")
res59: Int = 2
キーがマップに含まれているかどうか不明な場合は、.getメソッドを使用することもできます。このメソッドはキーが存在する場合はSome(v)を、存在しない場合はNoneを返します:
@ m.get("one")
res60: Option[Int] = Some(1)
@ m.get("four")
res61: Option[Int] = None
マップは他のコレクションと同じ操作をサポートしていますが、各キー-値ペアを表すタプルのコレクションとして扱われます。.toによる変換には変換元となるタプルのコレクションが必要で、+演算子はタプルをキー-値ペアとしてマップに追加します。forループはタプルを反復処理します:
@ Vector(("one", 1), ("two", 2), ("three", 3)).to(Map)
res62: Map[String, Int] = Map("one" -> 1, "two" -> 2, "three" -> 3)
@ Map[String, Int]() + ("one" -> 1) + ("three" -> 3)
res63: Map[String, Int] = Map("one" -> 1, "three" -> 3)
@ for ((k, v) <- m) println(k + " " + v)
one 1
two 2
three 3
セットと同様に、マップを反復処理する際の要素の順序は定義されておらず、依存すべきではありません。また、ほとんどの不変マップ操作の時間計算量はマップのサイズに対してO(log n)となります。
4.2.5 不変リスト
val myList = List(1, 2, 3, 4, 5)
myList: List[Int] = List(1, 2, 3, 4, 5)
@ myList.head
res66: Int = 1
@ val myTail = myList.tail
myTail: List[Int] = List(2, 3, 4, 5)
@ val myOtherList = 0 :: myList
myOtherList: List[Int] = List(0, 1, 2, 3, 4, 5)
@ val myThirdList = -1 :: myList
myThirdList: List[Int] = List(-1, 1, 2, 3, 4, 5)
Scalaの不変リストは単方向連結リストのデータ構造です。リストの各ノードは値と次のノードへのポインタを持ち、末尾にはNilノードが配置されます。リストには高速なO(1)時間で最初の要素を取得可能な.headメソッド、最初の要素を除いた新しいリストを生成するO(1)時間の.tailメソッド、そして先頭に要素を1つ追加するO(1)時間の::演算子が用意されています。
.tailと::が効率的なのは、既存のリストの大部分を共有できるためです。.tailは単方向連結構造における次のノードへの参照を返すのに対し、::は先頭に新しいノードを追加します。複数のリストがノードを共有できるという事実により、上記の例ではmyList、myTail、myOtherList、myThirdListは実際にはほとんど同じデータ構造となっています:

これにより、例えばファイルシステム上のパスのように片側の要素がすべて同一であるような大量のコレクションを扱う場合、メモリ使用量を大幅に削減できます。配列をO(n)時間で更新コピーしたり、ベクトルをO(log n)時間で更新コピーしたりする代わりに、リストに要素を先頭に追加するのは高速なO(1)操作です。
リストの欠点として、myList(i)によるインデックス参照はO(n)時間の低速な操作となります。これは目的の要素を見つけるために左からリスト全体を辿る必要があるためです。また、リストの右側で要素を追加/削除する操作もO(n)時間と低速です。これはリスト全体をコピーする必要があるためです。高速なインデックス参照や右側での高速な追加/削除が必要な場合は、代わりにVectors(4.2.1)または可変配列Deques(4.3.1)の使用を検討するべきです。
4.3 可変コレクション
可変コレクションは、インプレース操作を行う場合、不変コレクションに比べて一般に処理速度が速いという特徴があります。ただし、可変性には代償が伴います。プログラムの異なる部分間でこれらを共有する際には、より慎重な取り扱いが求められます。共有された可変コレクションが予期せず更新されることでバグが発生するケースが多く、大規模なコードベースの中でどの行が意図しない更新を行っているのかを突き止めるのは困難な作業となります。 一般的なアプローチとしては、パフォーマンスのボトルネックが存在する関数内やクラスのプライベート領域では可変コレクションを使用し、速度が最優先事項ではない箇所では不変コレクションを使用する方法が推奨されます。これにより、最も重要な部分では可変コレクションの高いパフォーマンスを享受しつつ、アプリケーションロジックの大部分では不変コレクションが提供する安全性を損なうことなく維持することが可能になります。
4.3.1 可変配列デック
配列デックは汎用的な可変型の線形コレクションであり、効率的なO(1)時間でのインデックス参照、インデックス位置への更新、および左右両端での要素の挿入・削除をサポートします:
val myArrayDeque = collection.mutable.ArrayDeque(1, 2, 3, 4, 5)
myArrayDeque: collection.mutable.ArrayDeque[Int] = ArrayDeque(1, 2, 3, 4, 5)
myArrayDeque.removeHead()
// res71: Int = 1
myArrayDeque.append(6)
// res72: collection.mutable.ArrayDeque[Int] = ArrayDeque(2, 3, 4, 5, 6)
myArrayDeque.removeHead()
// res73: Int = 2
myArrayDeque
// res74: collection.mutable.ArrayDeque[Int] = ArrayDeque(3, 4, 5, 6)
配列デックは循環バッファとして実装されており、バッファ内のコレクションの論理的な先頭位置と末尾位置を示すポインタが存在します。上記の操作は左から右へ以下のように視覚化できます:
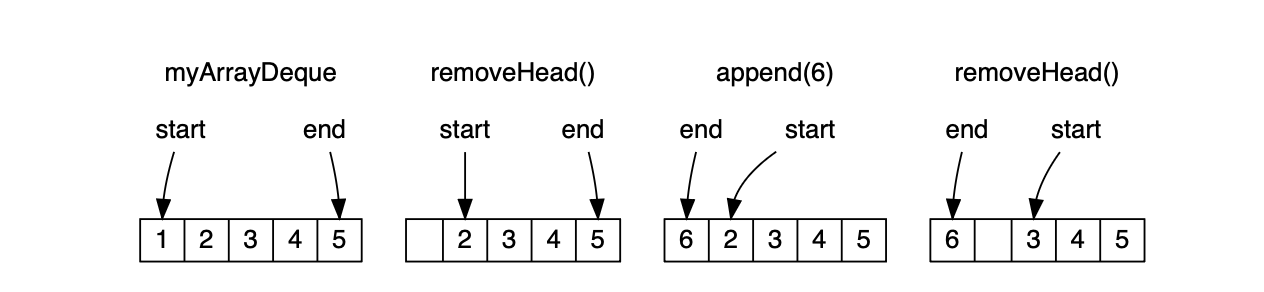
ArrayDequeは、可能な限り同じ基礎配列を再利用しようとします。要素の追加や削除が行われる際には、開始位置と終了位置のポインタのみを移動させます。基礎配列の再割り当てが行われるのは、要素の総数が現在の容量を超えた場合に限られ、その際の再割り当てコストを抑えるため、配列のサイズは固定倍率で増加します。 このため、ArrayDequeに対する操作は、操作ごとにO(log n)個の新しいツリーノードを割り当てる必要がある不変のVectorに比べて大幅に高速です。 ArrayDequeは標準的な操作群(4.1節参照)をサポートしており、さまざまな用途に活用できます:
- 拡張可能な配列:
Array.newBuilderは配列構築中のインデックス参照や変更を許可しませんが、Arrayは要素の追加自体ができません。ArrayDequeではこれら両方の操作が可能です。 - コード内で要素の追加/削除を:+/+:や.tail/.initで行う場合、これがボトルネックとなる場合、より高速で変更可能な代替手段として
ArrayDequeが適しています。ArrayDequeへの追加/先頭挿入操作は、同等のVector操作に比べてはるかに高速です。 - 右端への追加(.append)による先入れ先出し(FIFO)キューとしての機能
- 右端への追加と.removeHeadによる先入れ後出し(LIFO)スタックとしての機能
変更可能なArrayDequeを不変のVectorに"freeze"したい場合、.to(Vector)メソッドを使用できます:
myArrayDeque.to(Vector)
// res75: Vector[Int] = Vector(3, 4, 5, 6)
なお、この操作ではコレクション全体のコピーが作成されることに注意してください。 ArrayDequeは抽象コレクションのmutable.Bufferインターフェースを実装しており、collection.mutable.Buffer(…)構文でも作成可能です。
4.3.2 可変セット
Scala標準ライブラリでは、先に説明した不変セットに対応する形で、可変セットが提供されています。
可変セットも効率的な.containsチェック(O(1))をサポートしていますが、+や-演算子で新しいセットコピーを作成する代わりに、.addメソッドで要素を追加し、.removeメソッドで要素を削除します:
val s = collection.mutable.Set(1, 2, 3)
s: mutable.Set[Int] = HashSet(1, 2, 3)
s.add(4)
s.remove(1)
s.contains(2)
// res77: Boolean = true
s
// res81: mutable.Set[Int] = HashSet(2, 3, 4)
s.contains(4)
// res78: Boolean = false
可変セットを不変セットに「凍結」するには、.to(Set)メソッドを使用します。これにより、.addや.removeメソッドで変更できないコピーが作成され、同じ方法で再び可変セットに変換できます。なお、この変換を行うたびにセット全体のコピーが作成されることに注意してください。
4.3.3 可変マップ
可変マップは不変マップと基本的に同じですが、キーと値のペアを追加または削除することで内容を変更できる点が異なります:
val m = collection.mutable.Map("one" -> 1, "two" -> 2, "three" -> 3)
m: mutable.Map[String, Int] = HashMap("two" -> 2, "three" -> 3, "one" -> 1)
m.remove("two")
res83: Option[Int] = Some(2)
@ m("five") = 5
@ m
res85: mutable.Map[String, Int] = HashMap("five" -> 5, "three" -> 3, "one" -> 1)
可変マップには便利な getOrElseUpdate 関数が用意されています。この関数はキーを指定して値を検索し、もしその値が存在しない場合には計算してマップに格納します:
val m = collection.mutable.Map("one" -> 1, "two" -> 2, "three" -> 3)
m.getOrElseUpdate("three",
res87: Int = 3
-1) // 既に存在するため、既存の値を返します
@ m // `m` の内容は変更されません
res88: mutable.Map[String, Int] = HashMap("two" -> 2, "three" -> 3, "one" -> 1)
@ m.getOrElseUpdate("four",
res89: Int = -1
-1) // 存在しないため、新しい値をマップに格納してそれを返します
@ m // `m` には現在 "four" -> -1 が含まれます
res90: mutable.Map[String, Int] = HashMap(
"two" -> 2,
"three" -> 3,
"four" -> -1,
"one" -> 1
)
.getOrElseUpdate を使用すると、可変マップをキャッシュとして便利に活用できます。.getOrElseUpdate の第2引数は遅延評価される「名前付きパラメータ」であり、キーがマップ内に存在しない場合にのみ評価されます。これにより、「キーが存在するか確認し、存在すれば値を返す、存在しない場合は新規値を挿入してそれを返す」という一般的な処理フローが自然に実現できます。名前付きパラメータの詳細な仕組みについては第5章「注目すべきScalaの特徴」で詳しく解説します:
注目すべきScalaの特徴
可変マップはハッシュテーブルとして実装されており、m(...) による検索と m(...) = ... による更新はいずれも効率的な O(1) 操作です。
4.3.4 インプレース操作
配列を含むすべての可変コレクションには、一般的なコレクション操作のインプレース版が用意されています。 これらの操作を使用すると、変換されたコピーを作成することなく、元の可変コレクション上で直接操作を実行できます:
val a = collection.mutable.ArrayDeque(1, 2, 3, 4)
a: mutable.ArrayDeque[Int] = ArrayDeque(1, 2, 3, 4)
a.mapInPlace(_ + 1)
res92: mutable.ArrayDeque[Int] = ArrayDeque(2, 3, 4, 5)
@ a.filterInPlace(_ % 2 == 0)
res93: mutable.ArrayDeque[Int] = ArrayDeque(2, 4)
@ a // `a` はインプレースで変更されました
res94: mutable.ArrayDeque[Int] = ArrayDeque(2, 4)
上記で紹介したもの以外にも、dropInPlace、sliceInPlace、sortInPlaceなどの操作があります。通常の変換操作ではなくインプレース操作を使用することで、新しい変換済みコレクションを割り当てる際のオーバーヘッドを回避でき、パフォーマンスが重視される場面で有効です。
4.4 共通インターフェース
多くの場合、コードは処理対象のコレクションの具体的な種類を意識せずに動作します。例えば、順序付きの反復処理が必要なコードであれば、Seq[T]型のコレクションを使用できます:
def iterateOverSomething[T](items: Seq[T]) = {
for (i <- items) println(i)
}
@ iterateOverSomething(Vector(1, 2, 3))
1
2
3
@ iterateOverSomething(List(("one", 1), ("two", 2), ("three", 3)))
(one,1)
(two,2)
(three,3)
効率的なインデックス位置による要素取得が必要なコードの場合、それがArray型であろうとVector型であろうと問題ありませんが、List型とは連携できません。このようなケースでは、IndexedSeq[T]型のコレクションを使用できます:
def getIndexTwoAndFour[T](items: IndexedSeq[T]) = (items(2), items(4))
getIndexTwoAndFour(Vector(1, 2, 3, 4, 5))
// res99: (Int, Int) = (3, 5)
getIndexTwoAndFour(Array(2, 4, 6, 8, 10))
// res100: (Int, Int) = (6, 10)
これまでに見てきたデータ型の階層構造は以下の通りです:
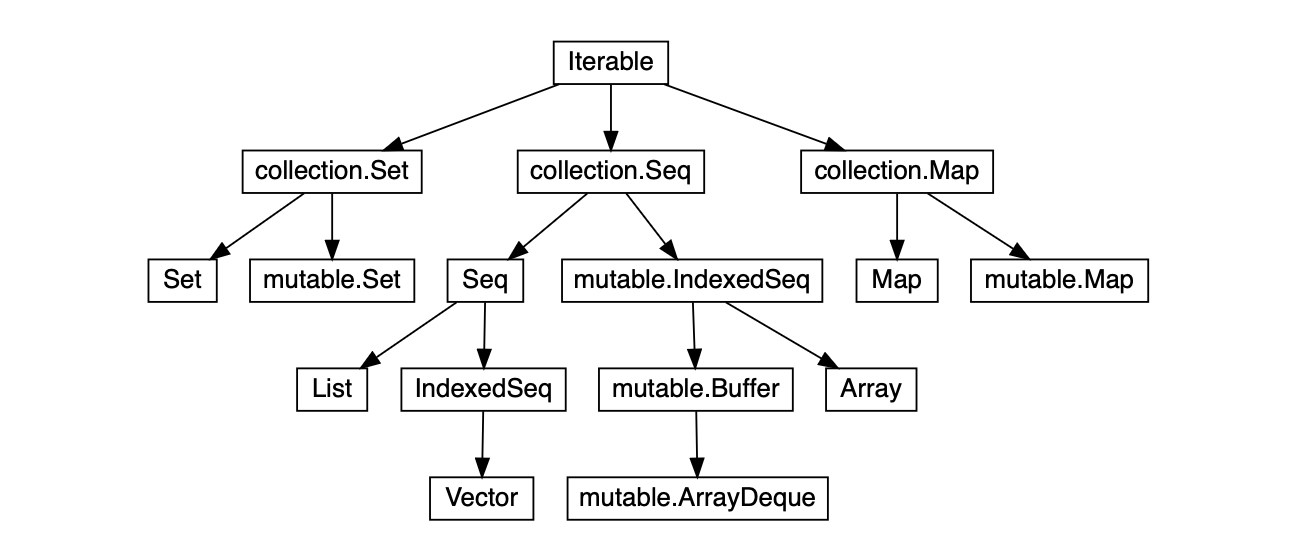
コードが処理すべきデータの種類に応じて、以下の階層から適切な型を選択できます:Iterable、IndexedSeq、Seq、collection.Seqなど。一般的に、ほとんどのコードではデフォルトで不変のSeq、Set、Mapが使用されます。collection.mutableパッケージに含まれる可変コレクションは、必要な場合にのみ使用し、関数内やクラスのプライベートメソッド内で局所的に使用することが推奨されます。collection.{Seq,Set,Map}は、可変コレクションと不変コレクションの両方に対する共通インターフェースとして機能します。
4.5 結論
本章では、Scala標準ライブラリの基盤となる基本的なコレクションについて解説しました。具体的には、配列、 不変のVector/Set/Map/List、および可変のArrayDeque/Set/Mapについて取り上げました。これらのコレクションの 構築方法、クエリの実行方法、相互変換の方法、さらには複数のコレクション型に対応できる関数の書き方について 説明しました。 本章を通じて、Scalaのコレクションライブラリを効果的に活用するための基礎を身につけていただけたことと思います。 このライブラリはScalaプログラムのあらゆる場面で広く使用されています。最後に、Scala言語のより特徴的な機能について いくつか紹介し、Scala入門の締めくくりとしたいと思います。
5 Notable Scala Features
@ def getDayMonthYear(s: String) = s match {
case s"$day-$month-$year" => println(s"found day: $day, month $month, year: $year")
case _ => println("not a date)
}
@ getDayMonthYear("9-8-1965")
found day: 9 month: 8, year: 1965
@ getDayMonthYear("9-8")
not a date
本章では、Scalaの特に興味深くユニークな機能のいくつかについて解説します。各機能について、その機能の動作内容と、実際の使用例をいくつか紹介することで、その有用性について直感的に理解できるようにします。 本章で扱うすべての機能が、日常的に使用するものばかりとは限りません。しかし、これらの使用頻度の低い機能であっても、実際に遭遇した際に適切に理解できるよう、ある程度の知識を持っておくことが有益です。
5.1 ケースクラスと封印トレイト
5.1.1 ケースクラス
ケースクラスは通常のクラスと似ていますが、「単なるデータ」を表現するクラスとして設計されています。具体的には、すべてのデータが不変で公開されており、可変状態やカプセル化は存在しません。その使用ケースは、C/C++の「構造体」、Javaの「POJO」、PythonやKotlinの「データクラス」に相当します。名称の由来は、caseキーワードによるパターンマッチング機能(5.2節参照)をサポートしている点にあります。 ケースクラスはcaseキーワードを用いて定義され、newキーワードを使わずにインスタンス化可能です。すべてのコンストラクタパラメータはデフォルトで公開フィールドとして扱われます。
@ case class Point(x: Int, y: Int)
@ val p = Point(1, 2)
p: Point = Point(1, 2)
@ p.x
res2: Int = 1
@ p.y
res3: Int = 2
ケースクラスには以下のような便利な機能が自動的に提供されます:
- コンストラクタのパラメータ値を表示する
.toStringメソッドが実装済み - コンストラクタのパラメータ値が等しいかどうかを判定する
==演算子が実装済み - ケースクラスインスタンスの修正コピーを簡単に作成できる
.copyメソッドが利用可能
@ p.toString
res4: String = "Point(1, 2)"
@ val p2 = Point(1, 2)
@ p == p2
res6: Boolean = True
@ val p = Point(1, 2)
@ val p3 = p.copy(y = 10)
p3: Point = Point(1, 10)
@ val p4 = p3.copy(x = 20)
通常のクラスと同様に、caseクラスの本体内でインスタンスメソッドやプロパティを定義できます:
@ case class Point(x: Int, y: Int) {
def z = x + y
}
@ val p = Point(1, 2)
@ p.z
res12: Int = 3
ケースクラスは、大きなタプルの優れた代替手段です。タプルの値を ._1 ._2 ._7 のようにインデックスで抽出する代わりに、.x や .y といった名前で直接値を取得できます。これは、大きなタプルのどのフィールドが ._7 に対応しているかを正確に記憶しておく必要がないため、はるかに簡単です!
5.1.2 封印されたトレイト
トレイトは封印(sealed)として定義することも可能で、その場合、拡張が許可されるのは事前に定義されたケースクラスの集合に限定されます。以下の例では、2つのケースクラス Point2D と Point3D によって拡張される封印トレイト Point を定義しています:
@ {
sealed trait Point
case class Point2D(x: Double, y: Double) extends Point
case class Point3D(x: Double, y: Double, z: Double) extends Point
}
@ def hypotenuse(p: Point) = p match {
case Point2D(x, y) => math.sqrt(x * x + y * y)
case Point3D(x, y, z) => math.sqrt(x * x + y * y + z * z)
}
@ val points: Array[Point] = Array(Point2D(1, 2), Point3D(4, 5, 6))
@ for (p <- points) println(hypotenuse(p))
2.23606797749979
8.774964387392123
通常のトレイトとsealedトレイトの本質的な違いは、以下のように要約できます:
- 通常のトレイトはオープンな性質を持ち、必要なすべてのメソッドを実装している限り、任意の数のクラスがそこから継承できます。また、これらのクラスのインスタンスは、トレイトが定義する必要なメソッドを通じて相互に置き換え可能です。
- 一方、sealedトレイトはクローズドな性質を持ち、継承を許可するクラスのセットは固定されています。すべての継承クラスは、トレイト自体と同じファイル内またはREPLコマンド内で定義されなければなりません(そのため、上記のPoint/Point2D/Point3Dの定義は波括弧{}で囲まれています)。
sealedトレイトPointから継承するクラスの数が固定されていることから、def hypotenuse関数内でパターンマッチングを使用し、各種類のPointをどのように処理するかを定義することが可能になります。
5.1.3 通常トレイトとsealedトレイトの使用ケース
通常のトレイトとsealedトレイトはどちらもScalaアプリケーションで広く使用されています。通常のトレイトは、任意の数のサブクラスを持つことができるインターフェースに適しており、sealedトレイトはサブクラスの数が固定されている場合に使用されます。 通常のトレイトとsealedトレイトはそれぞれ異なる種類の機能を簡単に実現できます:
- 通常のトレイト階層では、新しいサブクラスを追加するのは簡単です。単にクラスを定義し、必要なメソッドを実装するだけで済みます。ただし、新しいメソッドを追加するのは困難です。新しいメソッドは、既存のすべてのサブクラスに追加する必要があり、それらが多数存在する場合があるためです。
- sealedトレイト階層はその逆で、新しいメソッドを追加するのは簡単です。新しいメソッドは、各サブクラスに対してパターンマッチングを行い、それぞれに対して実行する処理を決定できます。ただし、新しいサブクラスを追加するのは困難です。既存のすべてのパターンマッチング箇所を変更し、新しいサブクラスを処理するためのケースを追加する必要があるためです。
一般的に、sealedトレイトは、サブクラスの数がほとんど変化しないか、まったく変化しないと予想される階層構造のモデリングに適しています。sealedトレイトでモデリングするのに適した典型的な例として、JSONが挙げられます:
@ {
sealed trait Json
case class Null() extends Json
case class Bool(value: Boolean) extends Json
case class Str(value: String) extends Json
case class Num(value: Double) extends Json
case class Arr(value: Seq[Json]) extends Json
case class Dict(value: Map[String, Json]) extends Json
}
- JSONの値として有効なのは、JSON null、ブール値、数値、文字列、配列、または辞書型のみです。
- JSONの仕様は20年間変更されていないため、今後このJSONトレイトに追加のサブクラスを定義する必要性が生じる可能性は低いでしょう。
- サブクラスの集合自体は固定されていますが、JSONデータに対して実行可能な操作の範囲は無限です:パース、シリアライズ、整形出力、圧縮、サニタイズなど、様々な処理が可能です。 このため、JSONデータ構造を通常のオープンなトレイト階層ではなく、閉じた封印型トレイト階層としてモデル化するのが適切です。
5.2 パターンマッチング
5.2.1 マッチング処理
Scalaでは「match」キーワードを使用して値に対するパターンマッチングを行うことができます。これは他のプログラミング言語における「switch文」と同様の機能ですが、より柔軟性に優れています。基本的な整数や文字列のマッチングに加え、タプルやケースクラスといった複合データ型から値を抽出する「分解」(destructuring)も可能です。以下の例の多くでは、「_ =>」のケースが記載されていますが、これはそれまでに定義されたどのケースにも該当しない場合のデフォルト処理を定義するものです。
@ def dayOfWeek(x: Int) = x match {
case 1 => "Mon"; case 2 => "Tue"
case 3 => "Wed"; case 4 => "Thu"
case 5 => "Fri"; case 6 => "Sat"
case 7 => "Sun"; case _ => "Unknown"
}
@ dayOfWeek(5)
res19: String = "Fri"
@ dayOfWeek(-1)
res20: String = "Unknown"
for (i <- Range.inclusive(1, 100)) {
val s = (i % 3, i % 5) match {
case (0, 0) => "FizzBuzz"
case (0, _) => "Fizz"
case (_, 0) => "Buzz"
case _ => 1
}
println(s)
}
1
2
Fizz
4
Buzz
...
((注意:文字列パターンに対するパターンマッチングでは、単純なグロブ風のパターンしかサポートしていません。正規表現のようなより複雑なパターンには対応していません。そのような場合は、scala.util.matching.Regexクラスの機能をご利用ください)
)
5.2.2 入れ子構造のパターンマッチング
パターンは入れ子構造にすることも可能です。例えば、以下の例ではケースクラス内の文字列パターンをマッチングしています:
@ case class Person(name: String, title: String)
@ def greet(p: Person) = p match {
case Person(s"$firstName $lastName", title) => println(s"Hello $title $lastName")
case Person(name, title) => println(s"Hello $title $name")
}
@ greet(Person("Haoyi Li", "Mr"))
Hello Mr Li
@ greet(Person("Who?", "Dr"))
Hello Dr Who?
パターンは任意の深さまで入れ子にすることができます。以下の例では、タプル内のケースクラス内の文字列パターンをマッチングしています:
@ def greet2(husband: Person, wife: Person) = (husband, wife) match {
case (Person(s"$first1 $last1", _), Person(s"$first2 $last2", _)) if last1 == last2 =>
println(s"Hello Mr and Ms $last1")
case (Person(name1, _), Person(name2, _)) => println(s"Hello $name1 and $name2")
}
@ greet2(Person("James Bond", "Mr"), Person("Jane Bond", "Ms"))
Hello Mr and Ms Bond
@ greet2(Person("James Bond", "Mr"), Person("Jane", "Ms"))
Hello James Bond and Jane
5.2.4 封印されたトレイトとケースクラスに対するパターンマッチング
パターンマッチングを使用すると、ケースクラスと封印されたトレイトで構成される構造化データを効率的に処理できます。 例えば、算術式を表現するシンプルな封印されたトレイトを考えてみましょう:
@ {
sealed trait Expr
case class BinOp(left: Expr, op: String, right: Expr) extends Expr
case class Literal(value: Int) extends Expr
case class Variable(name: String) extends Expr
}
ここでBinOpは「二項演算」を表します。この構造は、以下のような算術式を表現するのに使用できます:
x + 1 BinOp(Variable("x"), "+", Literal(1))
x * (y - 1) BinOp(
Variable("x"),
"*"
,
BinOp(Variable("y"),
"-"
, Literal(1))
) </> 5.22.scala
(x + 1) * (y - 1) BinOp(
"*"
BinOp(Variable("x"), "+", Literal(1)),
,
BinOp(Variable("y"),
"-"
, Literal(1))
)
現時点では、左側の文字列を右側の構造化ケースクラスに変換する解析処理については考慮しません:この部分は第19章「構造化テキストの解析」で解説します。代わりに、上記のような算術式をケースクラスとして解析した後に行いたい2つの操作について考えてみましょう:人間にとって読みやすい文字列として出力したい場合、あるいは特定の変数値を与えて式を評価したい場合です。
5.2.4.2 式の評価
式の評価は、文字列化するよりも少し複雑ですが、それほど大きな違いはありません。以下の要素が必要です:
・すべての変数の数値値を保持する values マップ
・+、-、* 演算子を異なる方法で処理すること
以下に評価関数の実装を示します:
@ def evaluate(expr: Expr, values: Map[String, Int]): Int = expr match {
case BinOp(left, "+", right) => evaluate(left, values) + evaluate(right, values)
case BinOp(left, "-", right) => evaluate(left, values) - evaluate(right, values)
case BinOp(left, "*", right) => evaluate(left, values) * evaluate(right, values)
case Literal(value) => value
case Variable(name) => values(name)
}
@ evaluate(smallExpr, Map("x" -> 10))
res56: Int = 11
@ evaluate(largeExpr, Map("x" -> 10, "y" -> 20))
res57: Int = 209 </> 5.27.scala
全体として、この実装は先に作成した文字列化関数と比較的似ています。expr: Expr パラメータに対してパターンマッチングを行う再帰関数で、Expr を実装する各ケースクラスを処理します。子要素を持たない Literal と Variable を扱うケースは単純ですが、BinOp ケースでは左右の子要素に対して再帰的に評価を行い、その結果を組み合わせます。これはどのプログラミング言語においても再帰データ構造を扱う一般的な手法であり、Scala の sealed トレイト、ケースクラス、パターンマッチングを活用することで、簡潔かつ容易に実装できます。
この Expr 構造体と、私たちが作成したプリンタおよび評価器は、意図的に簡素化された設計となっています。これは、パターンマッチングがケースクラスや封印されたトレイトとしてモデル化された構造化データを扱う際に、いかに簡潔かつ効果的に活用できるかを示すためです。これらの技術については、第20章『プログラミング言語の実装』でさらに深く掘り下げて解説します。
5.3 名前渡しパラメータ
@ def func(arg: => String) = ...
Scalaでは「名前渡し」メソッドパラメータもサポートしており、: => Tという構文で記述します。このパラメータはメソッド本体内で参照されるたびに評価されます。主な使用用途は以下の3点です:
- 引数が実際には使用されない場合の評価回避
- 引数の評価前後にセットアップ/クリーンアップ処理を実行するため
- 引数を複数回評価する必要がある場合
5.3.1 評価の回避
以下のlogメソッドでは、実際に出力されない限りmsg: => Stringパラメータの評価を行わないようにしています。これにより、ロギングが無効になっている場合でも、ログメッセージの構築にかかるCPU時間(この例では「Hello " + 123 + " World"」)を節約できます:
@ var logLevel = 1
@ log(2, "Hello " + 123 + " World")
Hello 123 World
@ def log(level: Int, msg: => String) = {
if (level > logLevel) println(msg)
@ logLevel = 3
}
@ log(2, "Hello " + 123 + " World")
<no output>
多くの場合、メソッドはすべての引数を常に使用するわけではありません。上記の例では、必要のない場合にログメッセージを計算しないことで、パフォーマンスが重視されるアプリケーションにおいてCPU時間とオブジェクト割り当てを大幅に削減できます。 第4章「Scalaコレクション」で取り上げたgetOrElseおよびgetOrElseUpdateメソッドも同様の仕組みです。これらのメソッドは、探している値が既に存在する場合、デフォルト値を表す引数を使用しません。デフォルト値を名前渡しパラメータにすることで、使用されない場合には評価を行わずに済みます。
5.3.2 評価のラップ処理
名前渡しパラメータを使用してメソッドの評価を「ラップ」し、セットアップ/クリーンアップ処理を囲むのは一般的なパターンです。以下のmeasureTime関数では、f: => Unitパラメータの評価を遅延させることで、引数の評価前後でSystem.currentTimeMillis()を実行し、処理時間を出力できます:
@ def measureTime(f: => Unit) = {
val start = System.currentTimeMillis()
f
val end = System.currentTimeMillis()
println("処理時間は " + (end - start) + " ミリ秒でした")
}
@ measureTime(new Array[String](10 * 1000 * 1000).hashCode())
処理時間は 24 ミリ秒でした
@ measureTime { // 単一引数を取るメソッドは中括弧でも呼び出せます
new Array[String](100 * 1000 * 1000).hashCode()
}
Evaluation took 287 milliseconds
このようなラップ処理には他にも多くの用途があります:
- 引数の評価中にスレッドローカルなコンテキストを設定する場合
- 引数をtry-catchブロック内で評価し、例外処理を可能にする場合
- Future内で引数を評価し、ロジックを別スレッドで非同期に実行させる場合 これらはすべて、名前渡しパラメータを使用することで効果的に解決できるケースです。
5.3.3 再試行評価
名前付きパラメータに関する最後のユースケースとして、メソッド引数の再評価について説明します。 以下のコードスニペットでは、汎用的な再試行メソッドを定義しています。このメソッドは引数を受け取り、try-catchブロック内で評価を行い、失敗した場合に最大試行回数まで再実行します。これをテストするために、失敗する可能性がある呼び出しをこのメソッドでラップし、コンソールに再試行メッセージが表示されることを確認します。
@ def retry[T](max: Int)(f: => T): T = {
var tries = 0
var result: Option[T] = None
while (result == None) {
try { result = Some(f) }
catch {case e: Throwable =>
tries += 1
if (tries > max) throw e
else {
println(s"失敗しました(再試行 #$tries)")
@ val httpbin = "https://httpbin.org"
@ retry(max = 5) {
// 成功確率は200レスポンスの場合のみ1/3
requests.get(
s"$httpbin/status/200,400,500"
)
}
}
}
result.get
} </> 5.31.scala
}
呼び出し失敗、再試行 #1
呼び出し失敗、再試行 #2
res68: requests.Response = Response(
"https://httpbin.org/status/200,400,500",
200,
... </> 5.32.scala
上記では、型パラメータ[T]を取る汎用関数としてretryを定義しています。この関数は名前付きパラメータを受け取り、型Tの値を計算し、コードブロックが成功した場合に初めてT型の値を返します。その後、任意の型のコードブロックをretryでラップすることができ、そのブロックを再試行して最初に正常に計算されたT型の値を返します。
retryが名前付きパラメータを取るように設計されていることで、requests.getブロックの評価を必要に応じて繰り返し実行することが可能になっています。再試行の他の使用例としては、パフォーマンスベンチマークの実行や負荷テストの実施などが挙げられます。一般的に、名前付きパラメータは頻繁に使用するものではありませんが、必要な場合にはメソッド引数の評価を様々な有用な方法で操作できる強力な機能を提供します:プロファイリング、再試行、省略処理などが可能になります。
上記のコードスニペットで使用したrequestsライブラリについては、第12章「HTTP APIとの連携」でより詳しく学習します。
5.4.1 Passing ExecutionContext to Futures
具体例を挙げると、Futureを使用するコードは動作するために ExecutionContext の値を必要とします。このため、この ExecutionContext をあらゆる場所で渡す必要が生じ、コードが煩雑で冗長になってしまいます:
def getEmployee(ec: ExecutionContext, id: Int): Future[Employee] = ...
def getRole(ec: ExecutionContext, employee: Employee): Future[Role] = ...
val executionContext: ExecutionContext = ...
val bigEmployee: Future[EmployeeWithRole] = {
getEmployee(executionContext, 100).flatMap(
executionContext,
e =>
getRole(executionContext, e)
.map(executionContext, r => EmployeeWithRole(e, r))
)
}
getEmployee メソッドと getRole メソッドは非同期処理を実行するため、まずこれらの処理をマッピングし、その後 flatMap を使ってさらに処理を連鎖させます。Future の動作原理そのものはこの章の範囲外ですが、重要なのはすべての操作で実行コンテキスト (executionContext) を指定する必要がある点です。この点については第13章で「Future を使ったフォーク・ジョイン並列処理」で改めて詳しく説明します。
暗黙的パラメータを使用しない場合、以下の選択肢があります:
実行コンテキストを明示的に渡す方法は冗長で、コードの可読性を低下させる可能性があります:本来注目すべきロジックが、大量の定型的な実行コンテキスト渡しの記述に埋もれてしまうのです。
実行コンテキストをグローバル変数として定義すれば簡潔になりますが、プログラムの異なる部分で異なる値を渡すという柔軟性が失われます。
スレッドローカル変数に実行コンテキストを格納する方法は簡潔さと柔軟性を両立できますが、エラーが発生しやすく、必要なコードを実行する前にスレッドローカル変数を設定するのを忘れる危険性があります。
これらの選択肢はいずれもトレードオフを伴い、簡潔さ、柔軟性、あるいは安全性のいずれかを犠牲にしなければなりません。Scala の暗黙的パラメータはこの問題に対する第四の解決策を提供します:実行コンテキストを暗黙的に渡すことで、上記の選択肢では得られない簡潔さ、柔軟性、安全性を同時に実現できるのです。
5.4.2 暗黙的パラメータによる依存性注入
これらの問題を解決するため、これらの関数すべてに実行コンテキストを暗黙的パラメータとして渡すように変更できます。これはFutureのflatMapやmapといった標準ライブラリの操作ですでに採用されている手法であり、getEmployee関数とgetRole関数も同様に修正可能です。実行コンテキストを暗黙的に定義することで、以下のメソッド呼び出しすべてで自動的に適切な値が取得されるようになります。
def getEmployee(id: Int)(implicit ec: ExecutionContext): Future[Employee] = ...
def getRole(employee: Employee)(implicit ec: ExecutionContext): Future[Role] = ...
implicit val executionContext: ExecutionContext = ...
val bigEmployee: Future[EmployeeWithRole] = {
getEmployee(100).flatMap(e =>
getRole(e).map(r =>
EmployeeWithRole(e, r)
)
)
}
</> 5.37.scala
暗黙的パラメータを使用することで、アプリケーション全体で共通のコンテキストや設定オブジェクトを明示的に渡す必要があるコードを簡潔に記述できます:
- 「重要度の低い」パラメータの渡し方を暗黙的に処理することで、読者の注意をアプリケーションの中核ロジックに集中させることができます。
- 暗黙的パラメータは明示的に渡すことも可能であるため、開発者が必要に応じて暗黙的パラメータを手動で指定したり上書きしたりする柔軟性を保持できます。
- 暗黙的パラメータが欠落している場合にコンパイル時エラーとなる性質により、スレッドローカル変数と比較してはるかにエラーが発生しにくくなります。暗黙的パラメータの欠落は、コードがコンパイルされて本番環境にデプロイされる前に早期に検出されます。
もちろんです!画像からの文字起こしを以下に示します。
5.5 型クラス推論
暗黙的パラメータが有用な第二の方法として、値を型に関連付けるために使用する方法があります。これはしばしば型クラスと呼ばれ、この用語はHaskellプログラミング言語に由来しますが、Scalaの「型」や「クラス」とは直接関係ありません。型クラスは前述の「implicit」言語機能を基盤とした技術ですが、本書のこの章で独自に解説するに値するほど興味深く重要な概念です。
5.5.1 問題設定:コマンドライン引数の解析
文字列として与えられたコマンドライン引数を、IntやBoolean、Doubleなど様々な型のScala値に変換する処理を考えてみましょう。これはほぼすべてのプログラムが直接的またはライブラリを介して対処しなければならない一般的なタスクです。
最初の大まかな設計として、値を解析する汎用メソッドを作成する方法が考えられます。そのシグネチャは以下のようなものになるでしょう:
def parseFromString[T](s: String): T = ...
val args = Seq("123", "true", "7.5")
val myInt = parseFromString[Int](args(0))
val myBoolean = parseFromString[Boolean](args(1))
val myDouble = parseFromString[Double](args(2))
表面的には、この実装は不可能に思えます:
parseCliArgumentメソッドは、与えられたstringをどのように任意の型Tに変換すればよいのでしょうか?- コマンドライン引数がどの型
Tに解析可能で、どの型には解析不可能かを、どのように判断すればよいのでしょうか?例えば、java.net.DatagramSocketのような型を入力文字列から解析することは許されません。
はい、承知しました。2つの入力文字列から文字起こしした内容を以下に示します。
5.5.2 個別のパーサーオブジェクトの定義
解決策の第二のアプローチとして、各解析対象タイプごとに個別のパーサーオブジェクトを定義する方法が考えられます。例えば以下のようになります:
trait StrParser[T]{ def parse(s: String): T }
object ParseInt extends StrParser[Int]{ def parse(s: String) = s.toInt }
object ParseBoolean extends StrParser[Boolean]{ def parse(s: String) = s.toBoolean }
object ParseDouble extends StrParser[Double]{ def parse(s: String) = s.toDouble }
</> 5.39.scala
これらのパーサーは以下のように呼び出せます:
val args = Seq("123", "true", "7.5")
val myInt = ParseInt.parse(args(0))
val myBoolean = ParseBoolean.parse(args(1))
val myDouble = ParseDouble.parse(args(2))
</> 5.40.scala
この方法は動作しますが、新たな問題が生じます。もし文字列を直接解析するのではなく、コンソールから値を読み取って解析するメソッドを記述したい場合、どうすればよいでしょうか?以下の2つの選択肢があります:
5.5.2.1 StrParserの再利用
第一の選択肢は、コンソールからの入力解析専用の新しいオブジェクトセットを定義する方法です:
trait ConsoleParser[T]{ def parse(): T }
object ConsoleParseInt extends ConsoleParser[Int]{
def parse() = scala.Console.in.readLine().toInt
}
object ConsoleParseBoolean extends ConsoleParser[Boolean]{
def parse() = scala.Console.in.readLine().toBoolean
}
object ConsoleParseDouble extends ConsoleParser[Double]{
def parse() = scala.Console.in.readLine().toDouble
}
val myInt = ConsoleParseInt.parse()
val myBoolean = ConsoleParseBoolean.parse()
val myDouble = ConsoleParseDouble.parse()
</> 5.41.scala
第二の選択肢は、StrParser[T]型の引数を受け取る補助メソッドを定義する方法です。このメソッドには、解析対象の型Tを指定する必要があります。
def parseFromConsole[T](parser: StrParser[T]) = parser.parse(scala.Console.in.readLine())
val myInt = parseFromConsole[Int](ParseInt)
val myBoolean = parseFromConsole[Boolean](ParseBoolean)
val myDouble = parseFromConsole[Double](ParseDouble)
</> 5.42.scala
どちらの解決策にも以下のような欠点があります:
第一の方法では、
Int/Boolean/Doubleなどの各パーサーを重複して定義する必要があります。ネットワークからの入力やファイルからの入力を解析する必要が生じた場合、各ケースごとにすべてのパーサーを複製しなければなりません。第二の方法では、これらの
ParseFooオブジェクトを至る所で渡す必要があります。多くの場合、StrParser[Int]は1つしか存在しません。parseFromConsole[Int]に直接渡せるはずです。なぜコンパイラがこれを自動的に推論できないのでしょうか?
5.5.3 解決策: 暗黙的 StrParser
前述の問題を解決するには、StrParser のインスタンスを implicit として定義します:
trait StrParser[T]{ def parse(s: String): T }
object StrParser{
implicit object ParseInt extends StrParser[Int]{
def parse(s: String) = s.toInt
}
implicit object ParseBoolean extends StrParser[Boolean]{
def parse(s: String) = s.toBoolean
}
implicit object ParseDouble extends StrParser[Double]{
def parse(s: String) = s.toDouble
}
}
</> 5.43.scala
implicit object である ParseInt、ParseBoolean などを、trait StrParser と同じ名前の object StrParser 内に配置します。定義されている class と同じ名前を持つ object は コンパニオンオブジェクト と呼ばれます。コンパニオンオブジェクトは、trait や class に関連する暗黙的変換、静的メソッド、ファクトリメソッドなどの機能をグループ化するためによく使用されます。コンパニオンオブジェクト内の暗黙的変換は特別な扱いを受け、明示的にインポートしなくても暗黙的パラメータとして使用できます。
Ammonite Scala REPL でこのコードを入力する場合、trait と object の両方が同じ REPL コマンド内で定義されるように、外側に追加の中括弧 {...} で囲む必要がありますのでご注意ください。
これで、以前のように ParseInt.parse(args(0)) と明示的に呼び出すことでリテラル文字列をパースできるだけでなく、パース対象の型に応じて適切な StrParser インスタンスを自動的に選択する汎用関数を記述できるようになります:
def parseFromString[T](s: String)(implicit parser: StrParser[T]) = {
parser.parse(s)
}
val args = Seq("123", "true", "7.5")
val myInt = parseFromString[Int](args(0))
val myBoolean = parseFromString[Boolean](args(1))
val myDouble = parseFromString[Double](args(2))
</> 5.44.scala
この実装は初期の設計案と似ていますが、(implicit parser: StrParser[T]) パラメータを引数として取ることで、関数が自動的に各型に適した StrParser インスタンスを推論できるようになりました。
5.5.3.1 StrParserの暗黙的再利用
StrParser[T]を暗黙的に定義することで、パーサーを重複して定義したり手動で受け渡したりすることなく、再利用が可能になります。例えば、コンソールから文字列を解析する関数を以下のように記述できます:
def parseFromConsole[T](implicit parser: StrParser[T]) = {
parser.parse(scala.Console.in.readLine())
}
val myInt = parseFromConsole[Int]
</> 5.45.scala
parseFromConsole[Int]を呼び出すと、StrParserのコンパニオンオブジェクトに定義されているStrParser.ParseIntの暗黙的変換が自動的に推論され、手動で複製したり煩雑に受け渡したりする必要がありません。これにより、適切なStrParserが存在する限り、汎用型Tを扱うコードを非常に簡潔に記述できます。
5.5.3.2 コンテキスト境界構文
この汎用型を持つ暗黙的パラメータを使用する手法は頻繁に使われるため、Scala言語ではこの目的に特化した構文が用意されています。以下のメソッドシグネチャ:
def parseFromString[T](s: String)(implicit parser: StrParser[T]) = ...
はより簡潔に次のように記述できます:
def parseFromString[T: StrParser](s: String) = ...
この構文はコンテキスト境界と呼ばれ、前述の(implicit parser: StrParser[T])構文と意味的に同等です。コンテキスト境界構文を使用する場合、暗黙的パラメータには名前が付与されないため、前述のようにparser.parseを呼び出すことはできません。代わりにimplicitly関数を使用して暗黙的値を解決する必要があり、例えばimplicitly[StrParser[T]].parseのように記述します。
5.5.3.3 コンパイル時の暗黙的変換安全性
Typeclass Inferenceが前述のimplicit言語機能を利用しているため、無効な型でparseFromConsoleを呼び出そうとするような誤りはコンパイル時にエラーとして検出されます:
@ val myDatagramSocket = parseFromConsole[java.net.DatagramSocket]
cmd19.sc:1: パラメータ`parser`に対する暗黙的値が見つかりませんでした:
ammonite.$sess.cmd11.StrParser[java.net.DatagramSocket]
val myDatagramSocket = parseFromConsole[java.net.DatagramSocket]
^
コンパイル失敗
</> 5.46.scala
同様に、(implicit parser: StrParser[T])型のパラメータを取るメソッドを、そのような暗黙的変換が利用できない別のメソッドから呼び出そうとすると、コンパイラがエラーを発生させます:
@ def genericMethodWithoutImplicit[T](s: String) = parseFromString[T](s)
cmd2.sc:1: パラメータ`parser`に対する暗黙的値が見つかりませんでした:
ammonite.$sess.cmd0.StrParser[T]
def genericMethodWithoutImplicit[T](s: String) = parseFromString[T](s)
^
コンパイル失敗
</> 5.47.scala
Typeclass Inferenceで実現した多くの機能は、実行時リフレクションでも実現可能です。しかし、実行時リフレクションに依存する方法は不安定で、誤りやバグ、設定ミスが本番環境に混入した場合、致命的な障害を引き起こす可能性が高くなります。一方、Scalaのimplicit機能を使用すれば、同じ結果をより安全に達成できます。誤りはコンパイル時に早期に検出され、本番環境の障害対応に追われることなく、余裕を持って修正することが可能です。
5.5.4 再帰的な型クラス推論
すでに述べたように、型クラスの手法を用いることで、解析対象の型に基づいて適切な StrParser を自動的に選択することが可能です。この手法はより複雑な型にも適用でき、例えば Seq[Int]、(Int, Boolean)、さらには Seq[(Int, Boolean)] のような入れ子構造の型を指定すれば、コンパイラが自動的に必要な解析ロジックを構築してくれます。
5.5.4.1 シーケンスの解析
例えば、以下の ParseSeq 関数は、スコープ内に暗黙的な StrParser[T] が存在する任意の型 T に対して、StrParser[Seq[T]] を提供します:
implicit def ParseSeq[T](implicit p: StrParser[T]) = new StrParser[Seq[T]]{
def parse(s: String) = s.split(',').toSeq.map(p.parse)
}
ここで定義した暗黙オブジェクトは、先に定義したシングルトンオブジェクトとは異なり、型 T に応じて異なる StrParser[T] が必要となります。したがって、異なる StrParser[Seq[T]] も必要になります。implicit def ParseSeq は、呼び出されるたびに異なる型 T に対して異なる StrParser を返すことになります。 この単一の定義により、Seq[Boolean]、Seq[Int]、その他のシーケンス型を解析することが可能になります。
@ parseFromString[Seq[Boolean]]("true, false, true")
res99: Seq[Boolean] = ArraySeq(true, false, true)
@ parseFromString[Seq[Int]]("1,2,3,4")
res100: Seq[Int] = ArraySeq(1, 2, 3, 4)
私たちが実質的に行っているのは、任意の型Tに対して、暗黙的なStrParser[T]が利用可能である限り、 コンパイラがStrParser[Seq[T]]を生成する方法を教えることです。すでにStrParser[Int]、 StrParser[Boolean]、StrParser[Double]が利用可能であるため、ParseSeqメソッドは StrParser[Seq[Int]]、StrParser[Seq[Boolean]]、StrParser[Seq[Double]]を無償で提供します。 ここでインスタンス化するStrParser[Seq[T]]には、パラメータs: Stringを受け取り、 Seq[T]を返すparseメソッドが備わっています。必要な変換ロジックを実装するだけでよく、 その実装は上記のコードスニペットで行っています。
5.5.4.2 タプルの解析
Seq[T]を解析するための暗黙的なdefを定義した方法と同様に、タプルの解析も同様に行うことができます。 以下では、タプルが入力文字列内でkey=valueの形式で表現されていると仮定して実装します:
implicit def ParseTuple[T, V](implicit p1: StrParser[T], p2: StrParser[V]) =
new StrParser[(T, V)]{
def parse(s: String) = {
val Array(left, right) = s.split('=')
(p1.parse(left), p2.parse(right))
}
}
この定義により StrParser[(T, V)] が生成されますが、これは特定の型 T と型 V に対してのみ有効です。これらの型に対して StrParser が利用可能である場合に限ります。これにより、= で区切られたペアとしてタプルを解析できるようになります:
@ parseFromString[(Int, Boolean)]("123=true")
res102: (Int, Boolean) = (123, true)
@ parseFromString[(Boolean, Double)]("true=1.5")
res103: (Boolean, Double) = (true, 1.5)
5.5.4.3 入れ子構造の解析
前述の2つの定義(暗黙的定義のParseSeqとParseTuple)があれば、タプルのシーケンスやシーケンスのタプルも
解析することが可能になります:
@ parseFromString[Seq[(Int, Boolean)]]("1=true,2=false,3=true,4=false")
res104: Seq[(Int, Boolean)] = ArraySeq((1, true), (2, false), (3, true), (4, false))
@ parseFromString[(Seq[Int], Seq[Boolean])]("1,2,3,4,5=true,false,true")
res105: (Seq[Int], Seq[Boolean]) = (ArraySeq(1, 2, 3, 4, 5), ArraySeq(true, false, true))
この場合、入力文字列を単純に分割する方法では、入れ子になった Seq[Seq[T]] やタプルのネスト構造を扱うことができない点に注意が必要です。より構造化されたパーサーであればこのようなケースも問題なく処理でき、任意に複雑な出力型を指定することが可能です。必要なパーサーは自動的に推論されるため、私たちはこの手法を第8章で解説するJSONおよびバイナリデータのシリアライゼーションライブラリで採用します。このライブラリではこの技術が活用されています。 ほとんどの静的型付けプログラミング言語では、ある程度まで型を推論することが可能です。すべての式に明示的な型注釈が付けられていなくても、コンパイラはプログラムの構造に基づいて型を推論できます。型クラスの導出はこれとは逆のプロセスで、明示的な型を指定することで、コンパイラが目的の型の値を生成するために必要なプログラム構造を推論できるようになります。 上記の例では、基本的な型の扱い方――StrParser[Boolean]、StrParser[Int]、StrParser[Seq[T]]、StrParser[(T, V)]の生成方法――を定義するだけで、コンパイラは必要に応じてStrParser[Seq[(Int, Boolean)]]を生成する方法を自動的に導き出すことができます。
5.6 結論
本章では、Scalaの特に特徴的な機能について考察してきた。Caseクラスやパターンマッチングは日常的に使用する基本的な機能である一方、By-Nameパラメータ、暗黙的パラメータ、型クラス推論などはより高度な機能であり、通常はフレームワークやライブラリによって強制される場合にのみ使用される。 しかしながら、これらの機能こそがScalaという言語の本質を形成しており、主流の他の言語では実現が難しい複雑な問題をよりエレガントに解決する手段を提供している。 本章では、これらの機能の基本的な動機付けと使用事例について解説した。本書の残りの部分では、実際のコード例を通じてさらに多くの使用事例に触れることになるだろう。 本章は、Scalaプログラミング言語を単独で解説する最後の章となる。以降の章では、オペレーティングシステムとの連携、リモートサービスの利用、第三者ライブラリとの連携といった、より複雑なトピックについて紹介していく。これまでに学んだScala言語の基礎概念は、Scala言語そのものの理解から、実際の問題解決における実用的な活用に至るまで、あなたの視野を広げる上で大いに役立つだろう。
6 Scalaでアルゴリズムを実装してみよう
- 6.1 マージソート
- 6.2 プレフィックス探索
- 6.2 幅優先探索
- 6.2 最短経路問題
本章では、Scalaプログラミング言語を用いて、一般的なアルゴリズムの実装方法を段階的に解説していきます。これらのアルゴリズムは学校教育で広く教えられており、就職面接でも頻繁に出題されるため、おそらく既に目にしたことがあるでしょう。 Scalaでこれらのアルゴリズムを実装することで、個々の小規模な問題を解決する際にScalaプログラミング言語をより使いこなせるようになることを目的としています。さらに、第5章「Scalaの特徴的な機能」で取り上げた言語独自の機能が、これらのよく知られたアルゴリズムの実装をいかに簡素化できるかについても具体的に示します。これにより、後続の章で扱う、より広範な種類のシステム、API、ツール、技術へと段階的に取り組んでいく準備が整うでしょう。
6.1 マージソート
配列は最も基本的なデータ構造の一つで、固定長の一次元的な値の連続体です。配列に対して行う最も一般的な操作には、ソートと検索があります。マージソートは配列をソートする手法の一つで、処理速度と実装の簡潔さのバランスが取れたアルゴリズムです。その主要な手順は以下の通りです: 未整列のアイテム配列を用意する 配列が単一の要素で構成されている場合、すでにソート済みとみなす それ以外の場合、配列を半分に分割する 分割した2つの半分の配列をそれぞれマージソートでソートする 2つのソート済みの半分の配列を1つの統合されたソート済み配列に結合する これらの手順は再帰的です。複数の要素を含む配列をソートするには、それを半分に分割して各半分をソートする必要があります。以下に、未整列の配列 Array(4, 0, 1, 5, 3, 2) を例に、このプロセスを視覚的に説明します:

処理対象の配列は分割ごとに半分になるため、サイズ n の配列に対して行える分割の階層は O(log n) 層に限られます。 各階層では配列の分割と結合に O(n) 時間を要するため、最終的なアルゴリズムの計算量は O(n log n) となります。 これらの処理は以下のコードに対応します:
def mergeSort(items: Array[Int]): Array[Int] = {
if (items.length <= 1) items
else {
val (left, right) = items.splitAt(items.length / 2)
val (sortedLeft, sortedRight) = (mergeSort(left), mergeSort(right))
}
}
この翻訳は比較的単純です。mergeSort関数を定義し、配列を入力として受け取ります(現時点では要素型がIntにハードコードされています)。配列の長さが1の場合はそのまま返します。そうでない場合は、配列を半分に分割し、それぞれの半分をソートします。 残る唯一の処理は、2つの半分を再び結合することです。これは、sortedLeftとsortedRightの両方からアイテムを1つずつ読み取り、小さい方のアイテムを出力配列に追加することで実現できます。2つの既にソートされた配列を1つの結合されたソート済み配列に結合する処理の一例を以下に示します。この場合、結合後の配列の要素は左から右へと埋められていきます:
